
Intro
Looking for a time series database for your solution? Do you consider Amazon Timestream for LiveAnalytics as a potential candidate? Or are you seeking to advance your knowledge of it? If so, welcome to this article. We’ll delve into Amazon Timestream for LiveAnalytics. We’ll uncover its most valuable details. These details will empower you. They will give you the knowledge to use its power in your applications and solutions.
One small note that today we have two versions of Amazon Timestream available:
- Amazon Timestream for LiveAnalytics;
- Amazon Timestream for InfluxDB (new, launched on March 15, 2024).
So today, the Amazon Timestream service offers both these versions as its two time-series database engines of your choice. In short, with LiveAnalytics you get a serverless database engine, which scales automatically up and down. It provides you with a powerful ingestion layer, which can handle more than ten gigabytes of time-series data per minute. And, with the InfluxDB one you get an open-source database and millisecond response times.
In this article, we’ll focus on the LiveAnalytics version. We’ll cover its main features and their pitfalls. We’ll also cover storage and pricing, writes and reads, and migrations.
Before We Started
If you are new to Amazon Timestream for LiveAnalytics, we encourage you to read the How it works section of the Amazon Timestream developer guide. There, you will learn about all the basic terms and concepts. Specifically, memory and magnetic stores of the storage layer and dimensions and measure values of the table schema, so we can jump straight to the most essential parts of the main character.
Solutions with LiveAnalytics
At Klika Tech, an IoT focused company, we are not limited to Amazon Timestream for LiveAnalytics as the only time series database, but for many use cases in the IoT domain we believe it can be a great fit. One of the obvious ones is when we need to store and analyze sensor data for IoT applications in near-real-time.
For example, the simplest solution for collecting data from IoT devices can be the use of AWS IoT Core and routing the data to Amazon Timestream for LiveAnalytics through IoT Core rule actions. When you need to analyze, validate, and transform data before saving you can use any AWS compute service you like and utilize AWS SDK.
By default, there is no need to manage VPC with Timestream, so that your potential serverless solution for the IoT use case with AWS can look like this:
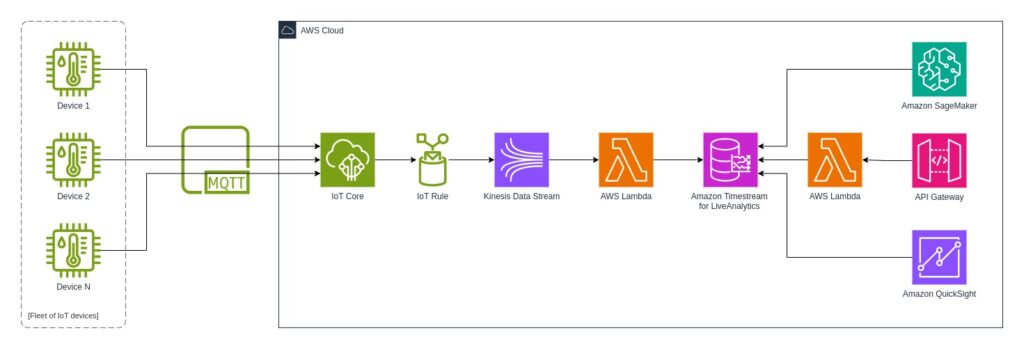
Additionally, there are many other ways of integrating Amazon Timestream for LiveAnalytics with a vast amount of AWS services and popular third-party tools.
For the LiveAnalytics version it’s hard to not highlight its ease of scaling. It automatically scales up or down without a need to manage the underlying infrastructure or provision capacity. Thanks to its decoupled architecture, each layer (Ingestion, Storage, and Query) is independently scalable.
Certainly, in order to build a successful solution, you need to know best practices and quotas of LiveAnalytics in depth. Below, we’re going to walk you through the most important things you need to take into account.
Data Modeling
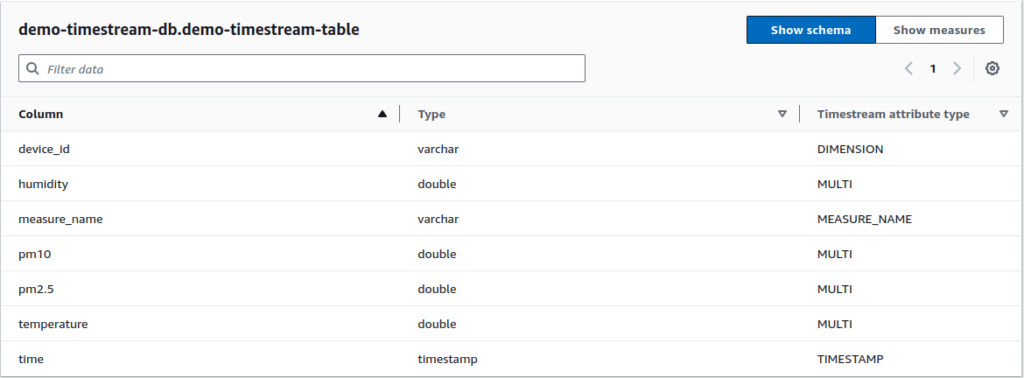
Here are the main tips for data modeling according to best practices:
- Prefer Multi-measure records over Single-measure records;
- Select attributes that don’t change over time for dimensions;
- Use the measure_name predicate to improve your query latency;
- Be aware of the limits of dimensions’ and measures’ names and values;
- Control partitioning with help of the customer-defined partition keys feature.
In cases where you are planning to have a couple of tables, consider keeping them in separate databases, by doing this you’ll get the following benefits:
- Active magnetic partitions of each database are not shared among tables, providing more bandwidth for writes into the Magnetic store;
- Better insights at monitoring each table individually with database metrics (ex.: ActiveMagneticStorePartitions, CumulativeBytesMetered, MemoryCumulativeBytesMetered, MagneticCumulativeBytesMetered).
You can create databases and tables using AWS CDK. Or, you can create them dynamically during runtime with the use of AWS SDK.
However, remember that the maximum is 500 databases allowed per AWS account at the time of writing this article.
Storage and Costs
Storage configuration of Amazon Timestream for LiveAnalytics consists of two main tiers: Memory, and Magnetic stores. Memory store is optimized for intensive writes, while the Magnetic store is better for analytical retrieval. The Magnetic store supports writes as well, but only to a certain extent. If you write to it, you need to monitor the ActiveMagneticStorePartitions metric.
Let’s imagine the next real world scenario where we set 1 hour for the Memory store and 1 year for the Magnetic store in the North Virginia region. If we assume that we keep 10TB per month on average in the Magnetic store it can cost us up to $300 (10000 GB x $0,03 per GB stored per month) according to pricing of Amazon Timestream. However, keeping 10TB in the Memory store for a month can be quite expensive – $259,200 (10,000 GB x $0,036 per GB stored per hour x 24 hours x 30 days). So, keep your retention periods for the Memory store as short as possible.
| Price for 1 day of Memory store | Price for 10 days of Memory store | Price for 30 days of Memory store | Price for month of Magnetic store | |
| 10 GB | $8.64 | $86.4 | $259.2 | $0.3 |
| 100 GB | $86.4 | $864 | $2592 | $3 |
| 1TB | $864 | $8,640 | $25,920 | $30 |
This calculation of costs makes you wonder, doesn’t it? Especially, In cases when the time window for writes is needed to be enlarged. For example, devices send collected events during a given period or historical data. For sure, things become much harder. Enabling writes to the Magnetic store using the EnableMagneticStoreWrites flag can be enough for sporadic writes, but it won’t be able to deal with intensive data streams. It causes throttling of writes to the Magnetic store for an indefinite time (even up to 6 hours). This is reflected in the ActiveMagneticStorePartitions metric of the database. The maximum number of active magnetic store partitions per database is 250.
Based on the above, calculate in advance the amount of data you’re planning to keep in the Memory store and think carefully about handling throttling of writes to the Magnetic store.
Writes
For writes you can consider the next two primary ways: the WriteRecords API operation or batch load. With WriteRecords you ingest a single data point or smaller batches of data in real-time, whereas with batch load you can perform historical data migrations. We’ll discuss the batch load in a separate section below dedicated for migrations, and in this section we’ll be focusing on writes via WriteRecords.
The first advice for WriteRecords is to ensure that timestamps in your data match the set retention period for the Memory store.
The second thing is to consider the usage of batches. It reduces latency and costs, and it improves performance.
There is one more important thing to consider – error handling. For ThrottlingException and 5XX exceptions you need to add retries and your retry strategy. For ThrottlingException of the Magnetic store with “ActiveMagneticStorePartitions” in the error message, you need to decide how to handle it. Instant retries for it may hurt your service. For example, you can create a dead letter queue for handling throttles of the Magnetic store later. Additionally, pay attention to RejectedRecordsException. It indicates duplicate data, data with timestamps outside of the retention period of the Memory store, or dimensions or measures that exceed the Timestream defined limits.
So, with that in mind, the code in TypeScript for writes to tables of Timestream for LiveAnalytics can look like this:
import {
_Record,
InternalServerException,
ResourceNotFoundException,
ThrottlingException,
TimestreamWriteClient,
TimestreamWriteServiceException,
ValidationException,
WriteRecordsCommand
} from "@aws-sdk/client-timestream-write";
import { ConfiguredRetryStrategy } from "@aws-sdk/util-retry";
const client = new TimestreamWriteClient({
region: 'us-east-1',
retryStrategy: new ConfiguredRetryStrategy(
4,
(attempt: number) => 100 + attempt * 1000
),
});
async function writeRecords(records: _Record[]) {
try {
const command = new WriteRecordsCommand({
DatabaseName: DATABASE_NAME,
TableName: TABLE_NAME,
Records: records,
});
await client.send(command);
} catch (error: TimestreamWriteServiceException | unknown) {
handleError(error);
}
}
function handleError(error: TimestreamWriteServiceException | unknown) {
if (error instanceof ResourceNotFoundException) {
console.error('ResourceNotFoundException: The specified database or table was not found.');
} else if (error instanceof ThrottlingException) {
if (error.message.includes('ActiveMagneticStorePartitions')) {
console.error(
'MagneticThrottlingException: The request was throttled due to exceeding the write rate to the Magnetic store (ActiveMagneticStorePartitions).',
);
} else {
console.error('ThrottlingException: The request was throttled due to exceeding the allowed request rate.');
}
} else if (error instanceof RejectedRecordsException) {
console.error('RejectedRecordsException: ' + error.message);
console.debug('Rejected records: ' + JSON.stringify(error.RejectedRecords, null, 2));
} else if (error instanceof InternalServerException) {
console.error('InternalServerException: An internal server error occurred.');
} else if (error instanceof ValidationException) {
console.error('ValidationException: The request parameters are invalid.');
console.error('Validation details:', error.message);
} else {
console.error('Unhandled Timestream error occurred:', error);
}
}Reads
To start querying LiveAnalytics from the code, you’ll need the Timestream client and the query command. For instance, in JavaScript you can utilize TimestreamQueryClient and QueryCommand. In the command you have to provide the query string, which should be an SQL statement.
As for SQL and its support, it’s used for retrieving time series data from one or more tables. In the Query language reference section, you can find a lot of useful features, however, with some limitations.
For querying with QueryCommand, there is one caveat. It’s important to differentiate MaxRows’ NextToken from the NextToken of a query, which is in progress. The MaxRows parameter replaces a traditional OFFSET to assist with pagination, and, you have to iterate your query while the progress of it is less than 100, then you can go to the next page with the NextToken. The following code block illustrates handling of NextToken with MaxRows:
import {
TimestreamQueryClient,
QueryCommand,
QueryCommandInput,
TimestreamQueryServiceException,
ResourceNotFoundException,
ThrottlingException,
InternalServerException,
ValidationException,
QueryCommandOutput,
} from "@aws-sdk/client-timestream-query";
const client = new TimestreamQueryClient({ region: 'us-east-1' });
async function query(NextToken: string | undefined = undefined): Promise<QueryCommandOutput> {
let input: QueryCommandInput = {
QueryString: `SELECT * FROM "${DATABASE_NAME}"."${TABLE_NAME}"`,
NextToken,
MaxRows: 100,
};
const command = new QueryCommand(input);
let result = await client.send(command);
if (result.NextToken && result?.QueryStatus?.ProgressPercentage! < 100) {
result = await query(result.NextToken);
}
return result;
}
async function readRecords() {
try {
let result: QueryCommandOutput = await query();
while (result.NextToken) {
result = await query(result.NextToken);
}
} catch (error: unknown) {
handleError(error);
}
}The following quotas are important for reading. They are: QueryString length, Data size for query result, and Timestream Compute Unit (TCU) per account. With Timestream Compute Unit (TCU) you can predict and control query costs.
Also, to make your queries cost less and run more efficiently, you can use scheduled queries.
Note, the document with best practices for querying consists of very useful tips. For instance, don’t use ORDER BY if it’s not needed, as it slows down the query performance. Applying the sort on the client side will be faster, if it’s possible, of course.
Migrations
When it comes to the schema migration for tables of LiveAnalytics, it can be achieved with the use of the following features: UNLOAD and batch load. UNLOAD is an SQL command for unloading data to a S3 bucket. Batch load is a tool for bulk writes. If your migrations are complicated, you may need an orchestration tool. As a good option for this purpose, you can try AWS Step Functions. Don’t forget to check the limitations of both features and Step Functions as well.
If a retention period of data is less than or equal to one year, you can increase the retention period of the Memory store till to 8,766 hours (approximately 1 year). So that all data during migration will be easily ingested via the batch load without throttling. However, when your data has a greater retention period than one year, you’ll have to split your migration into parts. The first part will go with the batch load tasks and the Memory store set to one year, as it’s the maximum allowed value. And the second part of data, which is older than one year, will be migrated with the use of the WriteRecords API or the batch load and with monitoring of the ActiveMagneticStorePartitions metric.
For writes to the Magnetic store during your migration, you need to be careful, as it’s very easy to get the spike of the ActiveMagneticStorePartitions metric. For large datasets, the WriteRecords API is a more preferable way. It’s slower than the batch load, but, on the other hand, it’s easier to handle errors. For example, you can pause the migration at any point. Then, wait till the moment when ActiveMagneticStorePartitions is back to normal (e.g. <= 200).
Alternatives
The simplest way to get the ranked list of time series databases is the DB-Engines site, where Amazon Timesteam for LiveAnalytics takes the 16th place among 44 time series databases. (Note: these statistics are applicable at the time of writing this article). It ranks databases based on their popularity.
Besides that list we can find other important players in this market:
- Azure Data Explorer
- Time Series Collections (MongoDB)
- Timeseries Insights API (Google Cloud)
- RedisTimeseries
Of course, to bring time series solutions to a common denominator is almost impossible. Selecting the appropriate time series database is a big challenge. There are many key factors to consider. These include scalability, performance, data model, retention policies, reliability, costs, and community and support. Only by evaluating these things, you can make the right decision whether it’s a match for your use case and requirements or not.
Summary
Amazon Timestream for LiveAnalytics is a fully managed, purpose-built time-series database for workloads from low-latency queries to large-scale data ingestion. The ingestion rate can be more than tens of gigabytes of time-series data per minute. Also, you can run SQL queries on terabytes of time-series data in seconds with up to 99.99% availability. Besides commands of AWS CLI and defining your cloud infrastructure in code with AWS CDK, you can create databases and tables on the fly with use of AWS SDK, and it’s absolutely fantastic!
However, you have to be careful with the following list of challenges you can face with this database:
- retention period of the Memory store and its costs;
- writes to the Magnetic store and monitoring ActiveMagneticStorePartitions;
- building your orchestration tool for complex schema migrations;
- migrations of huge amount of data with timestamps older than one year to the Magnetic store (very slow);
- quotas.
The summary highlights the core capabilities of Amazon Timestream for LiveAnalytics, as well as the important operational considerations and potential pain points that users should be prepared to address when working with this time-series database.
By Alexey Melekhavets, Senior Software Developer at Klika Tech, Inc.