
TABLE OF CONTENTS
Problem Statement
In the modern IT world, cloud technology plays a crucial role, offering unprecedented elasticity, flexibility, and scalability. One of the outstanding features of cloud environments is their ability to automatically scale out and scale in resources in response to demand. For example, AWS allows us to automatically scale the number of EC2 instances, managed by AWS ASG, by monitoring AWS CloudWatch metrics, such as the volume of HTTPS requests received by an AWS ALB.
This same scaling principle applies to a Kubernetes ecosystem, including Kubernetes clusters in AWS – AWS EKS. Aside from using AWS Fargate, which abstracts the need for manual infrastructure scaling by automatically managing container environments, it’s often necessary to scale Kubernetes nodes (EC2 instances) to accommodate increasing container workloads. Tools like the Cluster Autoscaler (CAS) have traditionally been employed to manage node scaling in AWS EKS, automatically adjusting node counts based on pod requirements.
CAS utilizes Amazon EC2 Auto Scaling Groups to manage AWS node groups and, eventually, EC2 machines.
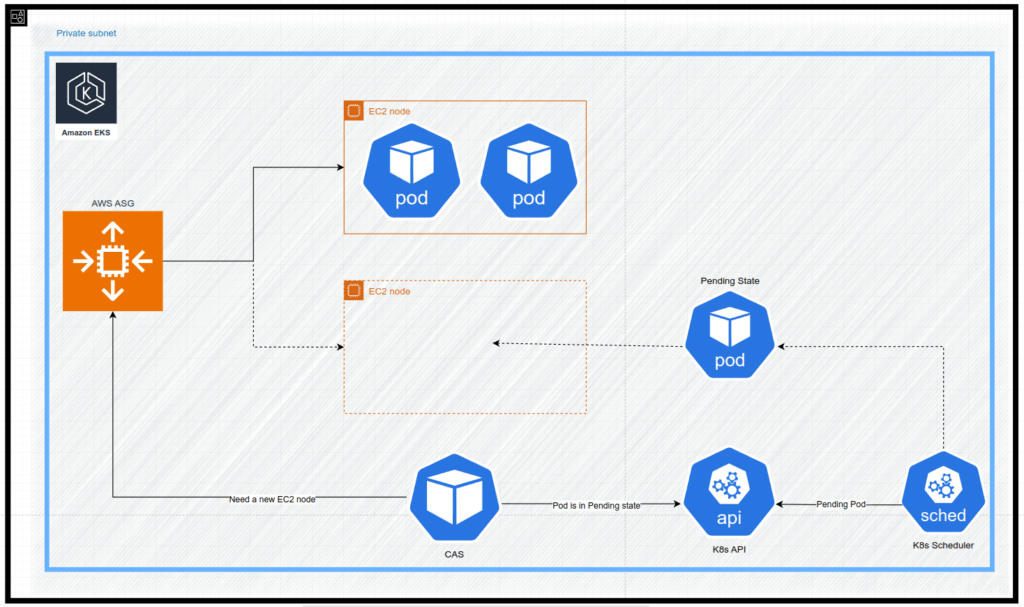
Lets take a look at the sequence of events resulting in provisioning of a new EC2 instance:
- A new pod is being created
- Kubernetes scheduler fails (due to lack of capacity) to schedule the new pod on an existing Kubernetes node
- The new pods are marked with “Pending“ state
- CAS is triggered and makes the API request to the AWS ASG
- AWS ASG provisions a new EC2 instance
- The new EC2 instance is joined to the AWS EKS as a new Kubernetes node
- Kubernetes scheduler succeeds in scheduling the new pod on the new Kubernetes node
- The new pod is starting on the new Kubernetes node
While the CAS can be used to scale out EC2 nodes, it comes with several significant limitations:
- it relies on static AWS ASG, which means the instance types are predefined and selected from a limited pool. This approach can lead to inefficiencies if workloads change significantly, as nodes may be oversized (inefficient AWS costs management) or undersized for the current pod requirements (decreasing application availability).
- it is not aware of Persistent Volume Claims (PVCs) and their corresponding Elastic Block Store (EBS) volumes, which can result in pod failures during startup. This occurs when the EC2 node, provisioned by CAS, is located in a different Availability Zone (AZ) than the EBS volume attached to the pod, leading to PVC volume mismatches and failure to mount.
- AWS ASG introduces some complexity, especially when managing multiple instance types, node pools, or capacity management. The different ASGs need to be configured and managed for different node types, leading to more complex management tasks.
- AWS ASG, functioning as an intermediary between CAS and the EC2 APi, introduces delays in the EC2 instances provisioning process decreasing application availability.
Hopefully, the challenges above can be solved by implementing the alternative HPA – Karpenter.
Karpenter Overview
Karpenter is an open-source node lifecycle management project built for Kubernetes.
The fact that Karpenter has reached a stable release demonstrates its maturity and readiness for production use, making it a leading Kubernetes HPA autoscaler now days.
In contrast to CAS, which relies on AWS ASG for node provisioning, Karpenter directly interacts with the Amazon EC2 API to manage EC2 instances.
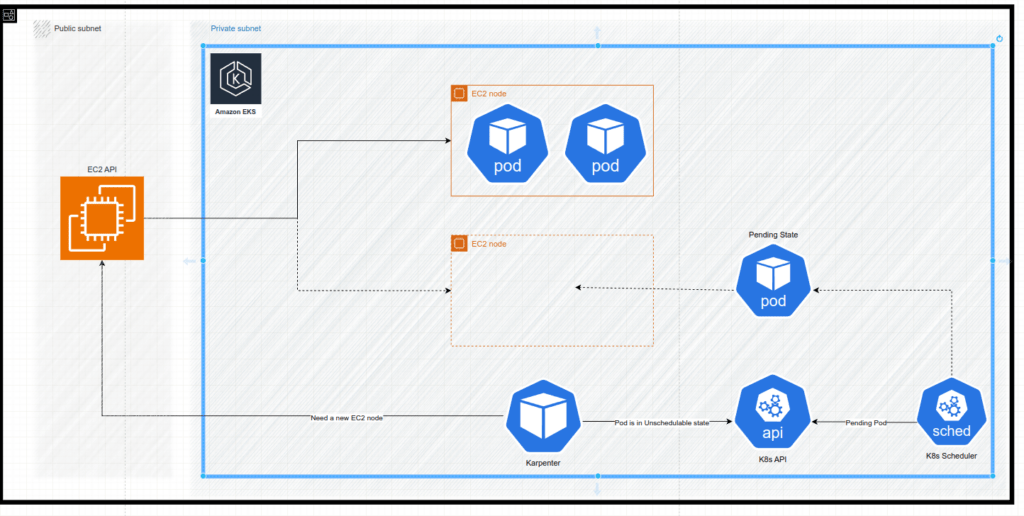
Lets take a look at the sequence of events resulting in provisioning of a new EC2 instance:
- A new pod is being created
- Kubernetes scheduler fails (due to lack of capacity) to schedule the new pod on a existed Kubernetes node
- The new pods is marked with “Unschedulable“ state
- Karpenter reads Kubernetes events, finds “Unschedulable“ pods, makes constraints calculations, resulting in making the API request to EC2 to provision EC2 instance
- A new EC2 instance is provisioned
- The new EC2 instance is joined to the AWS EKS as a new Kubernetes node
- Kubernetes scheduler succeeds in scheduling the new pod on the new Kubernetes node
- The new pod is starting on the new Kubernetes node
Concepts
In the following section, we will explore Karpenter’s key objects and delve into its core concepts
The Karpenter manages Kubernetes workloads by:
- Watching for pods that the Kubernetes scheduler has marked as unschedulable
- by observing events within the Kubernetes cluster
- Karpenter only attempts to schedule pods that have a status condition
Unschedulable=True, which the kube scheduler sets when it fails to schedule the pod to existing capacity.
- Evaluating scheduling constraints coming from:
- pods:
- resource requests, nodeselectors, affinities, tolerations, topology spread constraints, podDisruptionBudget, persistent volume topology, etc
- NodeClass:
- AWS VPC subnets, AWS Security groups (AWS SG), AWS EC2 instance AMI family, etc
- NodePools:
- node labels, node taints, instance-category, instance-family, AZ, CPU architecture, purchase option, etc
- pods:
- Provisioning nodes that meet the requirements of the pods
- directly requesting AWS EC2 API by sending commands to the underlying cloud provider.
- Disrupting the nodes when the nodes are no longer needed
NodeClasses
As mentioned above, Karpenter interacts with AWS EC2 API to provision EC2 instances. To specify how Karpenter should provision and manage nodes, including details such as instance types, AMIs, networking and storage configurations, and kubelet features, we create and configure NodeClasses.
The most important configurations there are:
## NodeClass
...
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: ${eks_cluster_name}
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: ${eks_cluster_name}
amiSelectorTerms:
- alias: al2@latest
role: ${karpenter_nodes_iam_role_name}
tags:
Name: "QA_node"
Department: development
Team: backend_development
...- subnetSelectorTerms and securityGroupSelectorTerms define the subnets karpenter provisions EC2 instances in and and AWS Security groups karpenter maps to instances.
amiFamilyandamiSelectorTermsdefine the family and AWS AMI images for EC2 isntances- role is the one which be attached to the instance profile of the provisioned EC2 instance
- tags – the tags to be assigned to EC2 intance
NodePools
Karpenter’s job is to add nodes to handle unschedulable pods, schedule pods on those nodes and remove the nodes when they are not needed. To instruct Karpenter how to manage unschedulable pods and configure nodes we create
The most important configurations there are:
## NodePool
...
spec:
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
limits:
cpu: "100"
memory: 500Gi
template:
metadata:
labels:
services: backend_development
spec:
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: <nane_of_the_relevant_nodeclass>
taints:
- effect: NoSchedule
key: services
value: backend_development
requirements:
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- t
- m
- c
...- consolidationPolicy defines conditions of considering a node consolidatable – see the section Disruption
- labels define the labels of kubernetes nodes
- nodeClassRef maps the NodeClass to the relevant NodeClass
- taints define the kubernetes node taints
- requirements defines what instance types, families, categories, CPU arch, etc to consider to provision EC2 instances
It is worth mention that we can use multiple NodePools in Karpenter. By managing multiple NodePools we could use different node constraints (such as no GPUs for a team), or use different disruption settings. Furthermore, we could isolate nodes for billing by specifying meaningful tags in NodeClasses.
One of the pivotal Karpenter features is that Karpenter prioritizes Spot offerings if the NodePool allows Spot and on-demand instances. So if the provider EC2 Fleet’s API indicates Spot capacity is unavailable, Karpenter eventually will attempt to provision on-demand instances, generally within milliseconds.
NodeClaims
Karpenter uses NodeClaims to manage the lifecycle of Kubernetes Nodes with the underlying cloud provider.
Karpenter will create and delete NodeClaims in response to the demands of Pods in the cluster. It does this by evaluating the requirements of pending pods, finding a compatible NodePool and NodeClass pair, and creating a NodeClaim which meets both sets of requirements.
Although NodeClaims are immutable resources managed by Karpenter, we can monitor NodeClaims to keep track of the status of your Nodes.
Scheduling
Karpenter launches nodes in response to pods that the Kubernetes scheduler has marked unschedulable. After solving scheduling constraints and launching capacity, Karpenter launches a machine in AWS.
Once Karpenter brings up a node, that node is available for the Kubernetes scheduler to schedule pods on it as well.
Karpenter’s model of layered constraints ensures that the precise type and amount of resources needed are available to pods, i.e. certain processors, AMI, AZ, etc.
There are three layers of constraints:
- Cloud Provider defines the first layer of constraints, including all instance types, architectures, zones, and purchase types available to its cloud
- The cluster administrator adds the next layer of constraints by creating one or more NodePools
- The final layer comes from you adding specifications to your Kubernetes pod deploymentsok
In the Problem statement section we noted, that CAS is storage-agnostic, meaning it lacks awareness of Persistent Volume Claims (PVCs) and their associated EBS volumes.
In contrast, Karpenter automatically detects storage scheduling requirements and includes them into node launch decisions. This significant improvement reduces the probability of pod failures during startup caused by mismatches between EBS volumes and pods provisioned across different Availability Zones.
One more important point we need to take into consideration in terms of configuring pods is that we should carefully configure resource requests and limits for workloads. Although Karpenter undoubtedly effectively optimizes and scales AWS EC2 instances, the end result depends on how well we have rightsized Kubernetes scheduling constraints, including but not limiting the pod requests. Karpenter does not consider limits or real resource utilization. For most workloads with non-compressible resources, such as memory, it is generally recommended to set requests and limits equally, because if a workload tries to burst beyond the available memory of the host, an out-of-memory (OOM) error occurs. Karpenter consolidation can increase the probability of this as it proactively tries to reduce total allocatable resources for a Kubernetes cluster.
Disruption
The Disruption concept generally refers to situations where workloads and/or nodes are affected due to scaling operations, interruptions (especially with spot instances), or other events that require the rebalancing of resources in a Kubernetes cluster.
The clue statements are:
- Finalizer:
- Karpenter places a finalizer bit on each node it creates. When a request comes in to delete one of those nodes (such as a TTL or a manual
kubectl delete node), Karpenter will cordon the node, drain all the pods, terminate the EC2 instance, and delete the node object. Karpenter handles all clean-up work needed to properly delete the node.
- Karpenter places a finalizer bit on each node it creates. When a request comes in to delete one of those nodes (such as a TTL or a manual
- Expiration:
- Karpenter will mark nodes as expired and disrupt them after they have lived a set number of seconds, based on the NodePool’s
spec.disruption.expireAftervalue. You can use node expiry to periodically recycle nodes due to security concerns.
- Karpenter will mark nodes as expired and disrupt them after they have lived a set number of seconds, based on the NodePool’s
- Consolidation
- Karpenter works to actively reduce cluster cost by identifying when:
- Nodes can be removed because the node is empty
- Nodes can be removed as their workloads will run on other nodes in the cluster
- Nodes can be replaced with cheaper variants due to a change in the workloads
- Karpenter works to actively reduce cluster cost by identifying when:
- Drift
- Karpenter will mark nodes as drifted and disrupt nodes that have drifted from their desired specification. See Drift to see which fields are considered.
- Interruption
- Karpenter will watch for upcoming interruption events that could affect your nodes (health events, spot interruption, etc.) and will cordon, drain, and terminate the node(s) ahead of the event to reduce workload disruption.
Conclusion
In recent years, Karpenter has quickly become a must-have tool for anyone managing a Kubernetes workload that uses Horizontal Pod Autoscaling. Its ability to dynamically provision nodes in real time, optimize resource allocation and reduce scaling latency sets it apart from traditional solutions like Cluster Autoscaler. Notably, Karpenter’s optimization of resource allocation not only improves efficiency but also leads to substantial reductions in cloud costs, making it a valuable asset for businesses.
While Karpenter originally started as an AWS-native solution, it has recently expanded its support to multiple cloud providers, making it a versatile tool for teams working in multi-cloud environments. This evolution underscores Karpenter’s growing importance in the Kubernetes ecosystem, where flexibility and scalability across cloud platforms are increasingly critical.
As organizations continue to adopt cloud-native technologies and seek ways to enhance their Kubernetes clusters, Karpenter offers a robust, flexible, and cost-efficient solution that can scale with their needs. Whether you’re just beginning to explore cloud-native infrastructure or you’re looking to optimize an existing Kubernetes environment, now is the perfect time to explore Karpenter. If you haven’t adopted it yet, it might just be the tool that transforms the way you manage infrastructure scaling in your cloud environment.
Links
https://karpenter.sh/docs/getting-started
By Pavel Luksha, Senior DevOps Engineer.