
TABLE OF CONTENTS
Introduction
Because AWS DynamoDB (DDB) is one of the most popular database solutions, numerous modelling libraries were created, which help developers get things done even more quickly. It is a great feeling when you can offload some work on external packages, but some might argue that the risks of adopting them are not worth it. In this blog, I will compare five popular DDB modelling libraries for JavaScript based on different factors, and we will go through examples where you can see how each library handles a particular situation. In addition, as a bonus, I will discuss when you don’t need to utilise one in your project. Note that basic DDB knowledge is required to understand the next chapters fully.
The libraries:
Let’s get started.
Initial View
| As of Oct 2023 | Dynamoose | TypeDORM | DynamoDB Toolbox | DynamoDB One Table | ElectroDB |
| Weekly Downloads | 75K | 49K | 40K | 15K | 19K |
| GitHub Stars | 2.1K | 0.4K | 1.6K | 0.6K | 0.8K |
| Last Release | Sep 2023 | Feb 2023 | May 2023 | Sep 2023 | Aug 2023 |
| Package Size | 393 kB | 1.75 MB + 325 kB | 270 kB | 827 kB | 528 kB |
| Documentation State (1-10) | 7 | 4 | 7 | 6 | 8 |
Regarding documentation, even though ElectroDB does not have a search bar, I gave it extra credit for real-life examples. In contrast, TypeDORM’s documentation consists of markdown files on GitHub mixed with code files.
At first glance, you may presume Dynamoose is the best choice, according to the stats from the table above. However, it is not that simple.
The package sizes might be very important when you deploy your app to Lambda and approach the size limit. TypeDORM seems to be way bigger than it should be despite the limited features it offers compared to other libraries.
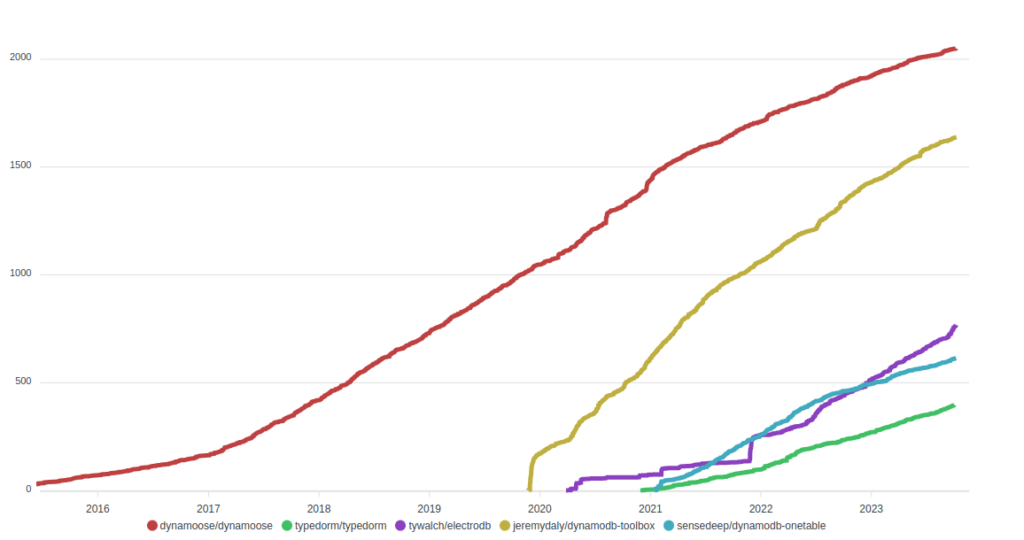
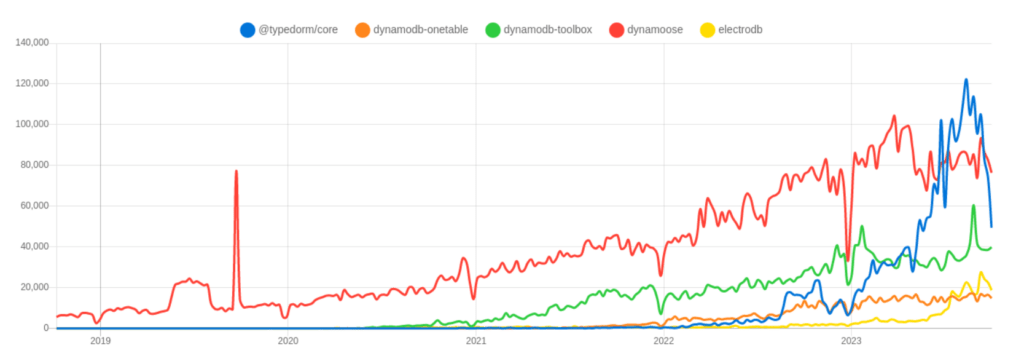
All packages except Dynamoose are relatively new. Despite that, TypeDORM managed to beat Dynamoose for a short period in terms of NPM downloads. Also, ElectroDB has started to gain more popularity among developers, according to the charts.
Example: Sensor Management
The source code of the example can be found here.
Prerequisites
To launch certain operations yourself, you must have the following installed:
- Node.js +18
- DynamoDB local
- Docker (optional)
- NoSQL workbench (optional)
Overview
This example is based on a table called “sensor-management”, which stores information about IoT sensors and their locations. Multiple entities are stored in the table according to the single-table design. Below, there is an image presenting how the entities are related to each other via the ER diagram:
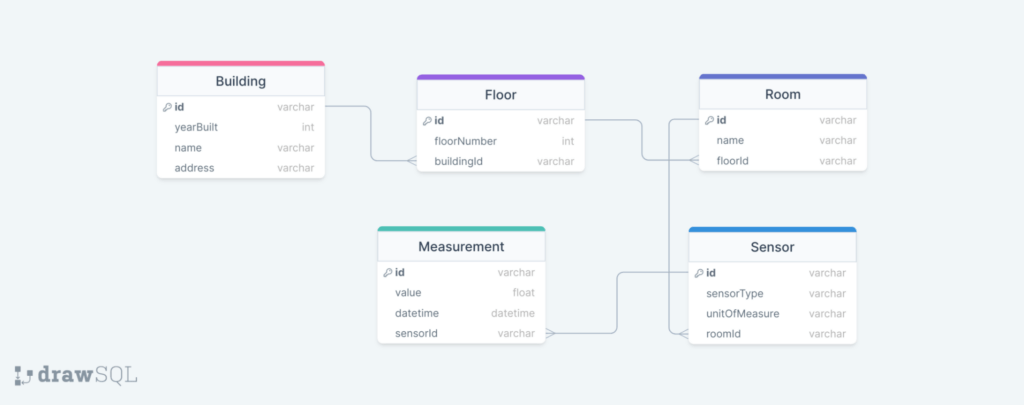
One building can have multiple floors; one floor can have multiple rooms; one room can have multiple sensors; one sensor can have multiple measurements.
We are interested in the following access patterns, which will help us model our table:
- Get building info
- Get the building’s floor info
- Get the floor’s room info
- Get the building’s sensor info
- Get the floor’s sensor info
- Get the room’s sensor info
- Get all items of a particular entity
- Get the latest measurement of a particular sensor
Eventually, you might end up with the following table and GSIs:
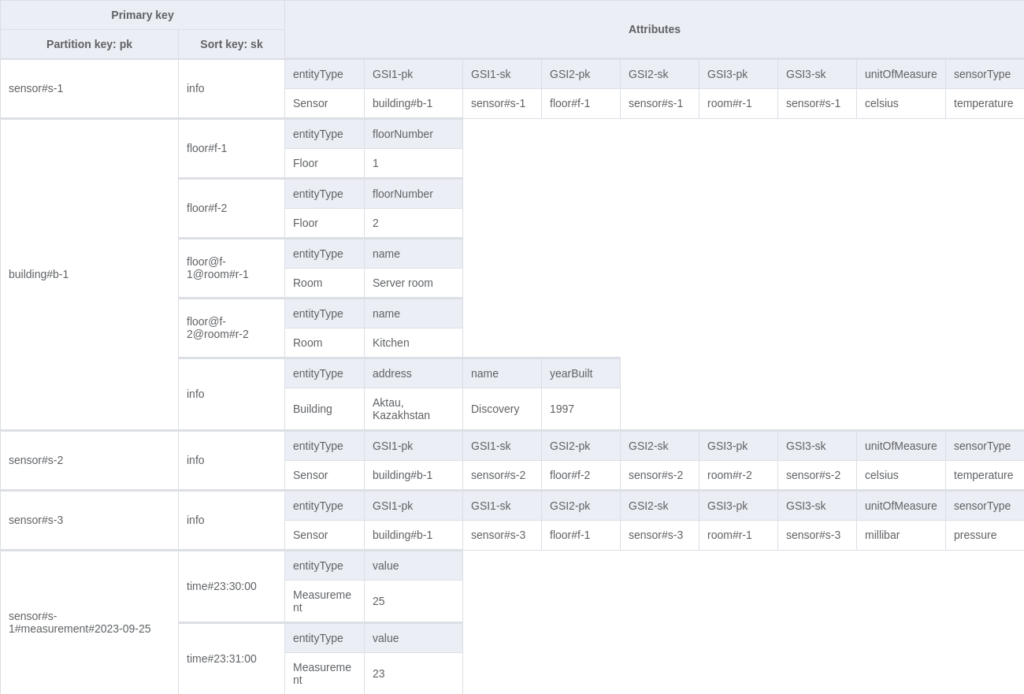
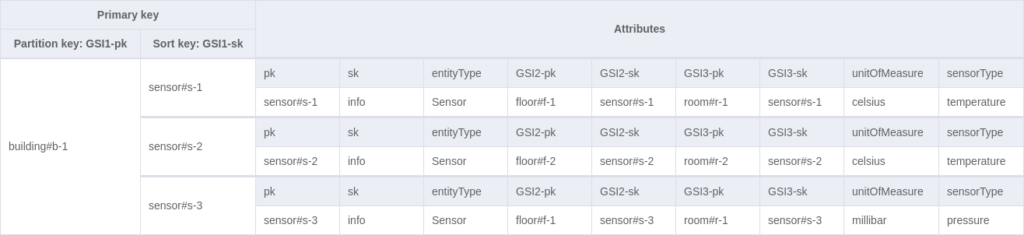
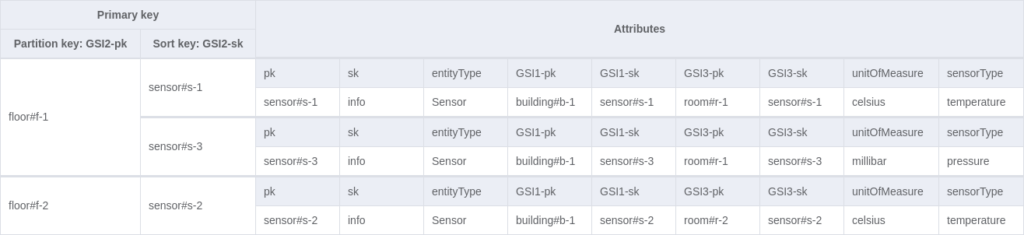
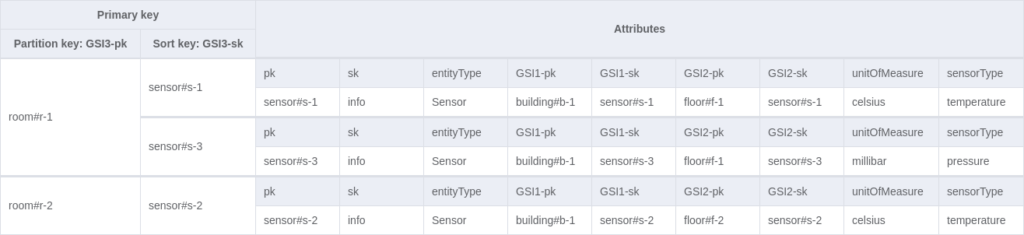
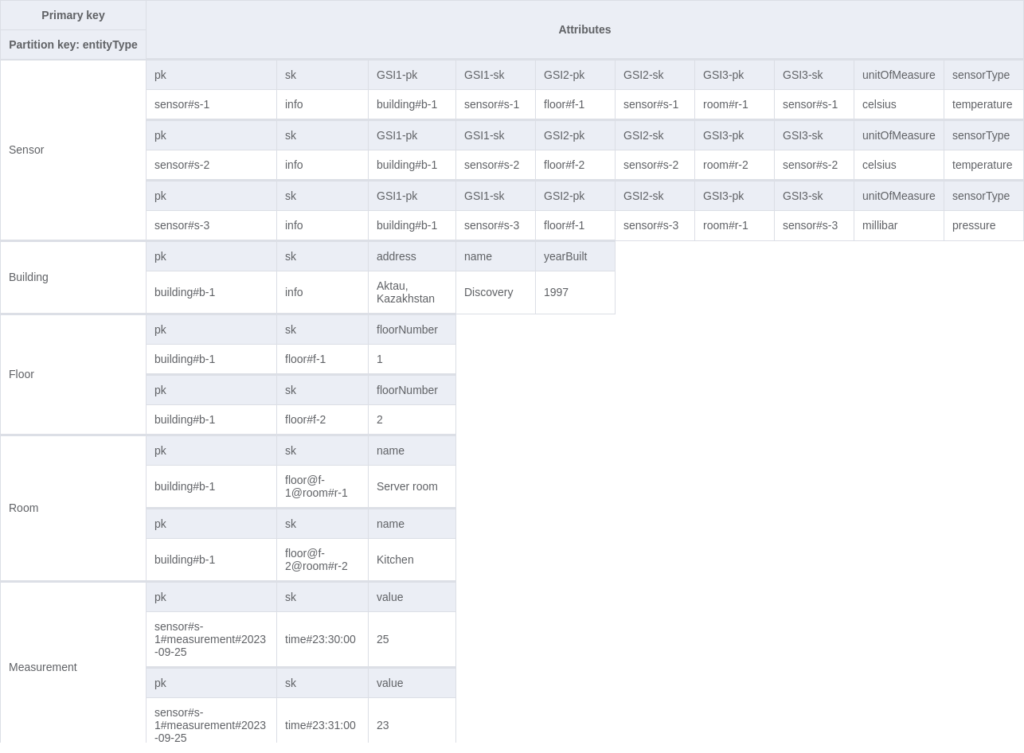
The table modelling steps and explanations can be found here.
Schema Definition
All libraries similarly approach schema modelling, but each has its own advantages and disadvantages. Let’s look at the Building entity schema using each solution.
Dynamoose
// src/dynamoose/entities/building.ts
export class BuildingItem extends Item {
id: string;
name: string;
address: string;
yearBuilt: number;
}
export const buildingSchema = new dynamoose.Schema({
pk: {
type: String,
hashKey: true,
alias: "id",
set: (value) => {
// before sending to DDB
return `building#${value}`;
},
get: (value) => {
// after receiving from DDB
return id.replace('building#', '');
},
},
sk: {
type: dynamoose.type.CONSTANT("info"),
default: "info",
rangeKey: true,
},
entityType: {
type: dynamoose.type.CONSTANT(EntityType.BUILDING),
default: EntityType.BUILDING,
index: {
name: GSI.GSI4,
type: "global",
},
},
name: { type: String, required: true },
address: { type: String, required: true },
yearBuilt: {
type: Number,
required: true,
validate: (value) => +value > 1900,
},
});
export const Building = dynamoose.model<BuildingItem>(
TABLE_NAME,
buildingSchema,
{
create: false,
update: false,
}
);
Dynamoose was initially created with the multi-table design in mind, where each model represents a separate table. Because of that, you might encounter some bugs when trying to embrace the single-table design. Nevertheless, its schema has standard valuable features for our table, such as field getters/setters for prefixes, default values and validator functions. To interact with the entity, you have to create the model, which by default creates a table (beware!).
In addition, to use type-safe code, you must create a class inherited from the Dynamoose Item class. Unfortunately, TypeScript support is still in beta.
TypeDORM
// src/typedorm/entities/building.ts
@Entity({
name: EntityType.BUILDING,
primaryKey: {
partitionKey: `building#{{id}}`,
sortKey: "info",
},
indexes: {
[GSI.GSI4]: {
type: INDEX_TYPE.GSI,
partitionKey: `{{entityType}}`,
sortKey: "", // yells if not specified
},
},
})
export class Building {
@Attribute()
id: string;
@Attribute()
address: string;
@Attribute()
name: string;
@Attribute()
yearBuilt: number;
@Attribute({ default: EntityType.BUILDING })
entityType: EntityType;
}
TypeDORM relies on decorators for the schema definition. I liked it for its brevity and type-safety out of the box. However, even though it has the biggest package size among others, I stumbled upon numerous bugs and limitations, which prevented me from implementing all access patterns.
DynamoDB Toolbox
// src/dynamodb-toolbox/entities/building.ts
export type BuildingItem = {
pk: string;
sk: "info";
entityType: EntityType.BUILDING;
name: string;
address: string;
yearBuilt: number;
};
export type BuildingCompositeKey = {
pk: string;
};
export const Building = new Entity<
EntityType.BUILDING,
BuildingItem,
BuildingCompositeKey,
typeof table
>({
name: EntityType.BUILDING,
attributes: {
pk: {
partitionKey: true,
prefix: “building#”,
},
sk: { sortKey: true, default: "info" },
entityType: {
type: "string",
required: false,
default: EntityType.BUILDING,
},
name: { type: "string", required: true },
address: { type: "string", required: true },
yearBuilt: { type: "number", required: true },
},
table,
} as const // TS support);
DynamoDB Toolbox provides a similar set of functionality as Dynamoose, and on top of that, the type-safety is implemented much better here. If the inferred types do not work for you, overlays can be utilised to make up for it.
You may notice that we did not use getters/setters as in Dynamoose for the prefix because there is a handy function which adds and removes the prefix automatically for you (`prefix`). However, if you still need to use them, there are alternative options (`transform` / `format`). The biggest limitation I noticed immediately was that all these functions were not triggered when constructing queries. Basically, you have to concatenate prefixes again before sending query requests.
DynamoDB One Table
// src/dynamodb-onetable/entities/building.ts
export const Building = {
pk: {
type: String,
value: "building#${id}",
},
sk: { type: String, value: "info" },
id: { type: String, required: true },
entityType: {
type: String,
value: EntityType.BUILDING,
},
name: { type: String, required: true },
address: { type: String, required: true },
yearBuilt: { type: Number, required: true, validate: /\d{4}/
},
} as const;
You may have guessed it. The library is specifically developed for the single-table design. It achieves the goal in a good and concise manner. Regardless, it would’ve been great to have a schema wrapper or TS type for autocompletion. Furthermore, it is only possible to validate fields with a regular expression. Thus, accepting a function would be very helpful for incorporating existing validators.
ElectroDB
// src/electrodb/entities/building.ts
export const Building = new Entity({
model: {
entity: EntityType.BUILDING,
version: "1",
service: TABLE_NAME,
},
attributes: {
id: {
type: "string",
required: true,
readOnly: true,
},
sk: {
type: "string",
default: "info",
readOnly: true,
validate: (value) => value !== "info",
},
entityType: {
type: "string",
default: EntityType.BUILDING,
readOnly: true,
set: () => EntityType.BUILDING,
},
name: { type: "string", required: true },
address: { type: "string", required: true },
yearBuilt: {
type: "number",
required: true,
validate: (value) => value < 1900,
},
},
indexes: {
building: {
pk: {
field: "pk",
composite: ["id"],
template: "building#${id}",
},
sk: {
field: "sk",
composite: ["sk"],
},
},
all: {
index: GSI.GSI4,
pk: {
field: GSI_MAP.GSI4.pk,
composite: ["entityType"],
},
},
},
});
ElectroDB might seem intimidating at first due to its bulky schema. This is primarily true because of the steeper learning curve, but after understanding its core features like services, collections and indexes, it becomes so much easier to organise your code consistently.
The `indexes` object is required for defining access patterns where the primary key access pattern is necessary. Without specifying them, you won’t be able to use entity queries.
Operations
Next, we will explore some operations from each library
Dynamoose
// src/dynamoose/operations/getBuildingFloors.ts
export const getBuildingFloors = async (buildingId: string) => {
return await Floor.query("pk")
.eq(buildingId)
.and()
.where("sk")
.beginsWith("") //prefix is added at the schema level
.exec();
};
As previously mentioned, the TypeScript support is not great, so we must know the field names without hints and warnings. That is to say, we could write anything else where `pk` and `sk` are used, and the only thing we may get is the runtime errors. Notice also that `beginsWith` contains an empty string just to avoid errors.
TypeDORM
// src/typedorm/operations/getBuildingFloors.ts
export const getBuildingFloors = async (buildingId: string) => {
return await entityManager.find(
Floor,
{
buildingId,
},
{
keyCondition: {
BEGINS_WITH: ”floor#”,
},
}
);
};
Although the TS hints are better here compared to Dynamoose, we have to know the floor’s prefix to construct the query (the building’s prefix is not required and is prepended automatically). Of course, you can create a helper for such cases, but there is still room for improvement.
DynamoDB Toolbox
// src/dynamodb-toolbox/operations/getBuildingFloors.ts
export const getBuildingFloors = async (buildingId: string) => {
return await Floor.query(`building#${buildingId}`, {
beginsWith: ”floor#”,
});
};
DynamoDB One Table
// src/dynamodb-onetable/operations/getBuildingFloors.ts
export const getBuildingFloors = async (buildingId: string) => {
const model = table.getModel("Floor");
return await model.find({
buildingId,
});
};
It seems DynamoDB One Table has learned from its competitors – no need for memorising or copy-pasting prefixes and field names. In addition, there is auto-completion for the entity name in `getModel`. However, we can completely leave the object empty inside `find`, and TS won’t yell.
Can it be further improved? Let’s find out next.
ElectroDB
// src/electrodb/operations/getBuildingFloors.ts
export const getBuildingFloors = async (buildingId: string) => {
const floor = table.entities.floor;
return await floor.query.floor({ buildingId }).go();
};So what do we have here:
- No hard-coded prefixes and field names
- Autocompletion
- TS errors if `buildingId` is missing in the query
It is all thanks to our schema definition, where we included this access pattern:
// src/electrodb/entities/floor.ts
export const Floor = new Entity({
…
indexes: {
floor: {
pk: {
field: "pk",
composite: ["buildingId"],
template: "building#${buildingId}",
},
sk: {
field: "sk",
composite: ["id"],
template: "floor#${id}",
},
},
…
},
});
Summary
We did not cover all features, such as update operations, transactions, etc., to get truly objective scores. Nonetheless, based on all that information, here is the ranking list of the libraries (from best to worst):
- ElectroDB 😍
- DynamoDB One Table 😀
- DynamoDB Toolbox 😀
- Dynamoose 😐
- TypeDORM 😒
Deciding the order between DynamoDB Toolbox and DynamoDB One Table was hard. The former provides better schema modelling, and the latter requires less work for constructing queries. Because schemas are less likely to change, what to put first became apparent.
Possible Risks and Considerations
While adding an external DB wrapper to the project may ease your development life, there are certain risks that you should be aware of:
- Performance: It is not uncommon for such libraries to perform extra checks via validations and DB calls, which are hidden from your view. Often, there is no straightforward way to avoid them, which might force you to write raw queries when required.
- Security: Your company might have strict compliance requirements, which forbid using unapproved packages.
- New features and bugs: It is not a secret that every wrapper tries to keep up with new DB upgrades and ship a bug-free product. Unfortunately, it might take some time before a given feature or bug would be supported or fixed by the library.
- Ceased support: There are a significant number of packages that got deprecated. Even AWS has recently archived their DDB mapper.
- Unnecessary complexity: Certain libraries require some learning time and introduce boilerplate, which is mostly detrimental for small projects. If you are already familiar with AWS SDK for DDB, I don’t see much value in adding a new dependency.
Conclusion
Undoubtedly, DynamoDB modelling libraries are productivity boosters that simply help things get done. However, you shouldn’t forget about the risks they implicate. We went through five DDB wrappers, which hopefully will make you decide what to or not to use in your current/next project.
Other useful sources of information:
By Ruslan Yeleussinov, Software Developer at Klika Tech, Inc.