
TABLE OF CONTENTS
OVERVIEW
Ensuring application availability, minimizing downtime and mitigating risk during releases are key objectives in modern software development and deployment practices.
These challenges can be addressed through progressive delivery, which is the process of releasing updates to a product in a controlled and gradual manner, typically combining automation and metric analysis to drive the automated promotion or rollback of the update.
Progressive delivery is often described as an evolution of continuous delivery, extending the speed benefits made in CI/CD to the deployment process. This is accomplished by limiting the exposure of the new version to a subset of users, observing and analyzing for correct behavior, then progressively increasing the exposure to a broader and wider audience while continuously verifying correctness.
Two popular strategies that represent progressive delivery are Blue Green and Canary deployments.
BLUE GREEN DEPLOYMENT METHODOLOGY
The fundamental idea behind Blue Green deployment is to shift traffic between two identical environments that are running different versions of your application. The blue environment represents the current application version serving production traffic. In parallel, the green environment is staged running a different version of your application. After the green environment is ready and tested, production traffic is redirected from blue to green. If any problems are identified, you can roll back by reverting traffic back to the blue environment. A Blue Green Deployment allows users to reduce the amount of time multiple versions are running at the same time.
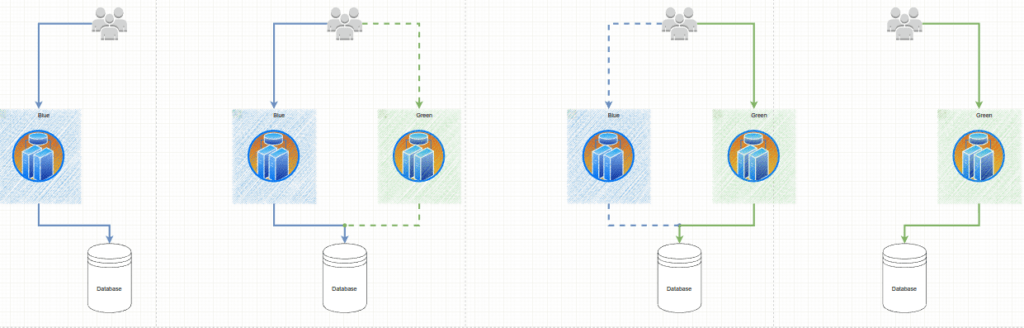
A key benefit of Blue Green deployments is the ability to simply roll traffic back to the operational (Blue) environment.
CANARY DEPLOYMENT METHODOLOGY
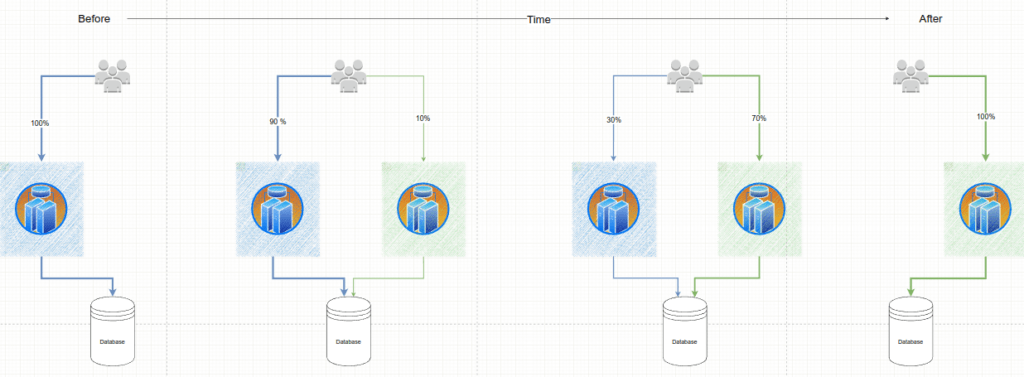
A Canary deployment exposes a subset of users to the new version of the application while serving the rest of the traffic to the old version. Once the new version is verified to be correct, the new version can gradually replace the old version. Ingress controllers and service meshes such as NGINX and Istio, enable more sophisticated traffic shaping patterns for canarying than what is natively available (e.g. achieving very fine-grained traffic splitting, or splitting based on HTTP headers).
BLUE/GREEN VS CANARY DEPLOYMENT
| BlueGreen Deployment: | Canary Deployment: | |
|---|---|---|
| Rollback Capabilities | 1. Rollback Simplicity: Rolling back is straightforward because the previous version (Blue) remains intact and can be switched back instantly if issues arise with the new version (Green). 2. Downtime Considerations: The switch between Blue and Green environments is typically seamless, minimizing downtime during rollback. | 1. Granular Rollback: Rollback in Canary deployments can be more complex, as it involves scaling down or stopping the new version gradually while scaling up the previous version. 2. Gradual Rollback: This method allows for more controlled rollbacks, especially if the issue only affects a small percentage of users. |
| Traffic Management | 1. Simplified Traffic Switching: Since only one environment is active at a time, switching traffic between Blue and Green is simple and doesn’t require fine-grained control. 2. No Need for Traffic Splitting: There’s no need for sophisticated traffic splitting, making it easier to manage with simpler infrastructure. | 1. Fine-Grained Traffic Control: Canary deployments benefit from advanced traffic management systems that can route specific percentages of traffic to different versions, enabling precise control over the rollout. 2. Progressive Rollouts: Traffic can be incrementally directed to the new version, allowing for real-time monitoring and adjustments. |
| Resource Utilization | 1. Resource Intensive: Requires duplicating the entire production environment, which can be resource-intensive, especially in large-scale systems. 2. Idle Resources: After the switch, the old environment is usually idle, which may lead to inefficient use of resources unless it’s quickly repurposed or decommissioned. | 1. More Efficient Use of Resources: Since only a portion of the environment is used for the new version at any time, it can be more resource-efficient, especially in cloud environments where resources are dynamically allocated. 2. Scaling Flexibility: TCan scale resources up or down based on the rollout stage, optimizing resource use over time. |
| Complexity and Risk | 1. Lower Complexity: Generally easier to implement, especially in environments with fewer dependencies and simpler infrastructure. 2. Lower Immediate Risk: The risk of immediate failure is lower because the entire environment can be validated before any traffic is switched. | 1. Higher Complexity: More complex to set up, requiring sophisticated monitoring, traffic management, and automated rollback systems. 2. Controlled Risk: Reduces risk over time by gradually exposing the new version to users, allowing for issues to be detected early without affecting all users. |
| Use Cases | Best For: Systems where simplicity, ease of rollback, and minimal downtime are priorities. Suitable for environments with strict uptime requirements and stateful applications. | Best For: Applications where gradual rollout, real-time user feedback, and minimizing risk during the release of new features are crucial. Ideal for large-scale, user-facing services where changes need to be tested progressively. |
DATA SYNCHRONIZATION LIMITATIONS
Data stores in modern application systems are a pivotal part of the infrastructure, serving as the backbone for storing, retrieving, and managing the vast amounts of data that power today’s applications. They ensure that data is available, reliable, and accessible to the various components of an application, from the user interface to the backend services.
Data stores must be designed to handle diverse data types and workloads, including structured data in relational databases and unstructured data in NoSQL databases.
When it comes to the Blue Green deployments from the relational database perspective, a general recommendation is to decouple schema changes from the code changes. This way, the relational database is outside of the environment boundary defined for the Blue/Green deployment and shared between the blue and green environments.
Apparently, decoupling schema changes from the code changes and sharing databases between the blue and green environments is not always feasible.
In these cases Blue Green Deployments Are Not Recommended:
Are your schema changes too complex to decouple from the code changes? Is sharing of data stores not feasible?
In some scenarios, sharing a data store isn’t desired or feasible. Schema changes are too complex to decouple. Data locality introduces too much performance degradation to the application, as when the blue and green environments are in geographically disparate regions. All of these situations require a solution where the data store is inside of the deployment environment boundary and tightly coupled to the blue and green applications respectively.
This requires data changes to be synchronized—propagated from the blue environment to the green one, and vice versa. The systems and processes to accomplish this are generally complex and limited by the data consistency requirements of your application. This means that during the deployment itself, you have to also manage the reliability, scalability, and performance of that synchronization workload, adding risk to the deployment.
In this article, we assume that the application is designed in a way so that it can share the same database during Blue Green deployments.
BLUE GREEN AND CANARY IMPLEMENTATION
ARGO ROLLOUTS OVERVIEW
There are many tools available on the market designed to facilitate Blue Green and Canary deployments in Kubernetes, such as Spinnaker, Flagger, and Argo Rollouts. In this article, we will focus on Argo Rollouts and demonstrate how it can be effectively employed to manage Blue Green deployments
Argo Rollouts is a Kubernetes controller and set of CRDs which provide advanced deployment capabilities such as:
- blue green deployments
- canary deployments
- integration with ingress controllers and service meshes for advanced traffic routing
- integration with metric providers for blue green & canary analysis
- automated promotion or rollback based on successful or failed metrics
We leverage Argo Rollouts because the native Kubernetes Deployment supports the RollingUpdate strategy which faces such limitations as:
- Few controls over the speed of the rollout
- Inability to control traffic flow to the new version
- Readiness probes are unsuitable for deeper, stress, or one-time checks
- No ability to query external metrics to verify an update
- Can halt the progression, but unable to automatically abort and rollback the update
HOW DOES THE ARGO ROLLOUTS CONTROLLER WORK
Similar to the deployment object, the Argo Rollouts controller will manage the creation, scaling, and deletion of ReplicaSets.
These ReplicaSets are defined by the plate field inside the Rollout resource, which uses the same pod template as the deployment object.
When the spec.template is changed, that signals to the Argo Rollouts controller that a new ReplicaSet will be introduced. The controller will use the strategy set within the spec.strategy field in order to determine how the rollout will progress from the old ReplicaSet to the new ReplicaSet. Once that new ReplicaSet is scaled up (and optionally passes an Analysis), the controller will mark it as “stable”.
USE CASES OF ARGO ROLLOUTS
- A user wants to run last-minute functional tests on the new version before it starts to serve production traffic. With the Blue Green strategy, Argo Rollouts allows users to specify a preview service and an active service. The Rollout will configure the preview service to send traffic to the new version while the active service continues to receive production traffic. Once a user is satisfied, they can promote the preview service to be the new active service.
- Before a new version starts receiving live traffic, a generic set of steps need to be executed beforehand. With the Blue Green Strategy, the user can bring up the new version without it receiving traffic from the active service. Once those steps finish executing, the rollout can cut over traffic to the new version.
- A user wants to give a small percentage of the production traffic to a new version of their application for a couple of hours. Afterward, they want to scale down the new version and look at some metrics to determine if the new version is performant compared to the old version. Then they will decide if they want to roll out the new version for all of the production traffic or stick with the current version. With the canary strategy, the rollout can scale up a ReplicaSet with the new version to receive a specified percentage of traffic, wait for a specified amount of time, set the percentage back to 0, and then wait to rollout out to service all of the traffic once the user is satisfied.
- A user wants to slowly give the new version more production traffic. They start by giving it a small percentage of the live traffic and wait a while before giving the new version more traffic. Eventually, the new version will receive all the production traffic. With the canary strategy, the user specifies the percentages they want the new version to receive and the amount of time to wait between percentages.
ARCHITECTURE OF ARGO ROLLOUTS
- Argo Rollouts controller
- main controller that monitors the cluster for events and reacts whenever a resource of type Rollout is changed.
- will only respond to those changes that happen in Rollout sources
- will not tamper with or respond to any changes that happen on normal Deployment Resources
- this means that you can install Argo Rollouts in a cluster that is also deploying applications with alternative methods.
- Rollout resource
- custom Kubernetes resource introduced and managed by Argo Rollouts
- mostly compatible with the native Kubernetes Deployment resource but with extra fields
- Replica sets for old and new version
- instances of the standard Kubernetes ReplicaSet resource
- but with some extra metadata on them in order to keep track of the different versions that are part of an application.
- Ingress/Service
- instances of the standard Kubernetes service resource
- but with some extra metadata needed for management.
- AnalysisTemplate and AnalysisRun
- Metric providers
ARGO ROLLOUTS DEPLOYMENT TO AWS EKS
In the article, we consider the AWS EKS as k8s workload orchestrator. So we need to deploy Argo Rollouts to the AWS EKS cluster, where the workload is currently running. There are several methods available for this deployment, including using the Argo Rollouts Helm chart. This flexibility allows us to select the deployment approach that best aligns with our company’s tools, techniques, and practices.
SOURCES
- https://github.com/argoproj/argo-rollouts
- https://argoproj.github.io/argo-rollouts
- https://docs.aws.amazon.com/whitepapers/latest/blue-green-deployments/welcome.html
By: Pavel Luksha, Senior DevOps Engineer